こんにちは、ソフトウェア開発に長く携わってきたBirmanです。
株式市場の動向を追う上で、ニュース分析は欠かせない要素ですよね。NewsAPIのような便利なツールを使えば、Pythonで手軽に株価に影響を与えそうな情報を収集・分析できると期待している方も多いでしょう。
しかし、私の長年の経験から言わせてもらうと、「とりあえず動くコード」と「実運用に耐えうるシステム」の間には、途方もなく深い溝があります。この溝を理解し、埋めていくことこそが、プロのエンジニアとしての真価であり、プロジェクトマネージャー(PM)として私が最も重視してきた点です。
この記事では、NewsAPIとTF-IDFを使った株価ニュース分析のアイデアをさらに一歩進め、「現場レベルのデータパイプライン構築」という切り口で解説します。単なるツールの使い方ではなく、ネットワークの不確実性、APIの制約、そして将来の拡張性まで見据えた、安定稼働するシステムを作るための思考法と具体的な実装の勘所をお伝えします。
コピペで動けばいい、という方には少し難しく感じるかもしれませんが、安定稼働するシステムを構築したいエンジニア、あるいはそのための設計思想を学びたい方には、きっと役立つはずです。
導入:なぜ「動くコード」だけでは実務で通用しないのか?
「とりあえず動いた」が招く悲劇:PMが経験したシステム停止の教訓
昔の話になりますが、私がまだ若手だった頃、安易な気持ちでWebAPIを使ったデータ連携システムを構築したことがありました。当時は「コードがエラーなく動けばOK」という認識で、エラーハンドリングもリトライも最低限。PMとしてそこまで深くは考えていなかったのです。
しかし、運用テスト時、そのシステムは時折、沈黙するようになりました。原因は、APIサーバーの一時的な応答遅延や、ネットワークの瞬断といった「予期せぬ不確実性」です。単発のリクエストなら問題なくても、24時間365日動かしていく中で、操作が途中で止まるが原因が特定できない、ログの情報で判断しきれない、という現象が起き不具合の解決に大きく時間を使ってしまいました。
この苦い経験は、私に「動くこと」と「運用できること」が全く別物であることを痛感させました。「堅牢性」「運用性」「拡張性」といった非機能要件を設計段階で深く考慮することの重要性を、身をもって学んだのです。それ以来、私はどんな小さなシステムでも、これらの視点を持って開発に臨むようになりました。
本記事で学ぶ「現場レベルのデータパイプライン構築」
本記事では、NewsAPIを使った株価ニュース分析を題材に、この「運用できるシステム」を構築するための思考法と具体的なアプローチを解説します。単なるコードの紹介に留まらず、プロの現場で必要とされる設計思想と実装テクニックを学ぶことで、あなたのシステム開発スキルは格段に向上するはずです。
設計編:NewsAPIで構築する株価ニュース分析パイプラインの全体像
NewsAPIは非常に便利なサービスですが、無料枠では1日100件というリクエスト制限があります。闇雲にAPIを叩いていては、あっという間に上限に達してしまい、肝心な時にデータが取れない、という事態になりかねません。
プロのエンジニアは、このようなAPIの制約に対して、効率的かつ賢く立ち向かいます。その鍵となるのが「キャッシュ戦略」と「差分更新」です。
無料枠を最大限に活かす!賢いデータ取得の「キャッシュ戦略」
「キャッシュ」とは、一度取得したデータを一時的に保存しておき、次回のリクエスト時にそのデータを再利用する仕組みです。これにより、不要なAPI呼び出しを減らし、無料枠のリクエスト数を節約できます。
アーキテクチャの概念図
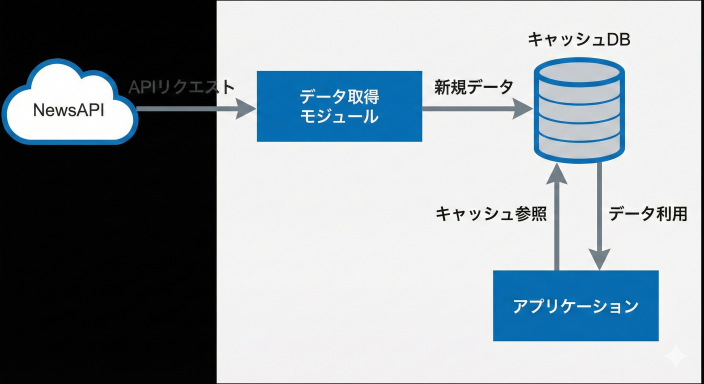
キャッシュすべきデータ項目としては、以下のようなものが考えられます。
article_id: 記事を一意に識別するID(NewsAPIのURLなどをハッシュ化したものなど)。重複排除と更新のキーとなります。title: ニュースのタイトル。description: ニュースの概要。url: ニュース記事のURL。published_at: ニュースの公開日時。fetched_at: キャッシュに保存した日時。
これらの情報をデータベース(例えばsqlite3のような軽量なDB)に保存することで、後から検索したり、分析したりする際にも役立ちます。
無駄をなくす「差分更新」のアーキテクチャ
毎日同じキーワードでニュースを取得すると、前日に取得した記事の多くが重複してしまいます。これでは無駄なAPIリクエストを大量に消費するだけです。
そこで導入するのが「差分更新」の考え方です。これは、「前回データを取得した日時以降の新規ニュースのみ」をAPIにリクエストする仕組みです。
NewsAPIにはfromパラメータがあり、これを活用することで、指定した日時以降に公開されたニュースのみを取得できます。キャッシュDBに最終取得日時を記録しておくことで、この差分更新を効率的に実現できます。
PM’s Eye 1: 「動くコード」と「運用できるシステム」の決定的な違い
若手エンジニアの皆さん、テスト環境でコードがエラーなく動いたからといって、それで安心していてはいけません。本番環境はテスト環境とは全く異なる「生き物」です。ネットワークは常に安定しているわけではありませんし、外部APIの応答も常に完璧とは限りません。
かつて、とあるプロジェクトで、メモリ1バイトを削るために徹夜でコードを最適化したものです。しかし、現代のシステム開発において、本当に重要なのは「いかに賢く、堅牢に、そして安定して動かすか」という非機能要件への配慮です。
例えば、
- 可用性: システムが常に利用可能であること。
- 信頼性: 障害が発生しても、適切に回復し、データが失われないこと。
- 保守性: コードが理解しやすく、変更や修正が容易であること。
- 拡張性: 将来の機能追加やアクセス増大に対応できること。
これらは、コードの機能(何ができるか)と同じくらい、あるいはそれ以上に重要な要素です。初期の設計段階でこれらの非機能要件を考慮し、適切な投資をしておくことで、後々の運用フェーズでのトラブル対応や改修にかかるコストを劇的に削減できると、長年の経験から断言できます。
実装編:堅牢なデータ取得と高精度な分析ロジック
ここからは、具体的なPythonコードを交えながら、前述の設計思想をどう実装していくかを見ていきましょう。
ネットワークの不確実性に対応する「指数バックオフ付きリトライ」
requestsライブラリは便利ですが、API呼び出しが失敗した際に自動で再試行する機能は持っていません。しかし、一時的なネットワークの問題であれば、少し時間を置いて再試行すれば成功するケースがほとんどです。
そこで、tenacityというPythonライブラリを導入します。これは、指数バックオフ(Exponential Backoff)と呼ばれる賢いリトライ戦略を簡単に実装できる優れものです。
指数バックオフとは?
エラーが発生するたびに、次のリトライまでの待機時間を指数関数的に長くしていく手法です(例: 1秒 -> 2秒 -> 4秒 -> 8秒…)。これにより、APIサーバーに過度な負荷をかけずに、自分のシステムが回復する可能性を高めます。
まず、tenacityをインストールします。
pip install tenacity次に、tenacityを使ってNewsAPIのデータ取得関数を堅牢にします。
import requests
import time
from datetime import datetime, timedelta
from tenacity import retry, wait_exponential, stop_after_attempt, retry_if_exception_type
# NewsAPIのキーとベースURLを設定
API_KEY = "YOUR_NEWS_API_KEY" # 実際のキーに置き換えてください
NEWSAPI_BASE_URL = "https://newsapi.org/v2/everything"
# 指数バックオフ付きリトライデコレータ
@retry(wait=wait_exponential(multiplier=1, min=4, max=10), # 1秒, 2秒, 4秒, 8秒... と待機
stop=stop_after_attempt(5), # 最大5回リトライ
retry=retry_if_exception_type(requests.exceptions.RequestException)) # requests関連の例外時のみリトライ
def fetch_news_with_retry(query, language="ja", from_date=None):
"""
NewsAPIからニュースを取得する関数(指数バックオフ付きリトライ対応)
Args:
query (str): 検索キーワード
language (str): ニュースの言語
from_date (str, optional): 指定した日時以降のニュースを取得 (YYYY-MM-DD形式). Defaults to None.
Returns:
list: ニュース記事のリスト (辞書形式), 失敗時は空リスト
"""
params = {
"q": query,
"language": language,
"sortBy": "publishedAt",
"apiKey": API_KEY
}
if from_date:
params["from"] = from_date
print(f"NewsAPIへリクエスト中: query='{query}', from='{from_date if from_date else 'all'}'")
response = requests.get(NEWSAPI_BASE_URL, params=params, timeout=10) # タイムアウトを設定
response.raise_for_status() # HTTPエラー (4xx, 5xx) があれば例外を発生させる
data = response.json()
# NewsAPIの無料枠は1日100件なので、取得件数に注意
if data.get("totalResults", 0) > 100:
print(f"注意: 取得可能な記事数が無料枠上限を超える可能性があります ({data['totalResults']}件)")
return data.get("articles", [])
# 使用例
# try:
# articles = fetch_news_with_retry("株価 上昇", from_date=(datetime.now() - timedelta(days=1)).strftime("%Y-%m-%d"))
# for article in articles:
# print(f"{article['publishedAt'][:10]} - {article['title']}")
# except Exception as e:
# print(f"最終的にNewsAPIリクエストに失敗しました: {e}")この@retryデコレータ一つで、ネットワークエラーやAPIサーバーの一時的な不調に対して、システムが粘り強く再試行するようになります。これは、システムの堅牢性を飛躍的に高める第一歩です。
APIコストを最適化する「データキャッシュ」の実装
次に、APIリクエスト数を節約するためのキャッシュ機構を実装します。今回は、手軽に利用できるsqlite3という軽量なデータベースを使ってみましょう。
import sqlite3
from datetime import datetime, timezone
DATABASE_FILE = "news_cache.db"
def init_db():
"""データベースの初期化とテーブル作成"""
conn = sqlite3.connect(DATABASE_FILE)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS articles (
id INTEGER PRIMARY KEY AUTOINCREMENT,
newsapi_url TEXT UNIQUE NOT NULL, -- NewsAPIのURLをユニークIDとして利用
title TEXT,
description TEXT,
url TEXT,
published_at TEXT,
fetched_at TEXT
)
""")
cursor.execute("""
CREATE TABLE IF NOT EXISTS last_fetch (
query TEXT PRIMARY KEY,
last_fetched_time TEXT
)
""")
conn.commit()
conn.close()
def save_articles_to_cache(articles):
"""取得したニュース記事をキャッシュDBに保存"""
conn = sqlite3.connect(DATABASE_FILE)
cursor = conn.cursor()
for article in articles:
newsapi_url = article.get("url") # NewsAPIが提供する記事URLをユニークキーとする
if not newsapi_url:
continue # URLがない記事はスキップ
try:
cursor.execute("""
INSERT INTO articles (newsapi_url, title, description, url, published_at, fetched_at)
VALUES (?, ?, ?, ?, ?, ?)
""", (
newsapi_url,
article.get("title"),
article.get("description"),
article.get("url"),
article.get("publishedAt"),
datetime.now(timezone.utc).isoformat()
))
except sqlite3.IntegrityError:
# UNIQUE制約違反 (既にキャッシュされている記事)
# print(f"記事 '{article.get('title')}' は既にキャッシュされています。")
pass # 更新の必要があればUPDATE文を使う
conn.commit()
conn.close()
def get_last_fetched_time(query):
"""指定クエリの最終取得日時を取得"""
conn = sqlite3.connect(DATABASE_FILE)
cursor = conn.cursor()
cursor.execute("SELECT last_fetched_time FROM last_fetch WHERE query = ?", (query,))
result = cursor.fetchone()
conn.close()
return result[0] if result else None
def update_last_fetched_time(query):
"""指定クエリの最終取得日時を更新"""
conn = sqlite3.connect(DATABASE_FILE)
cursor = conn.cursor()
cursor.execute("""
INSERT OR REPLACE INTO last_fetch (query, last_fetched_time)
VALUES (?, ?)
""", (query, datetime.now(timezone.utc).isoformat()))
conn.commit()
conn.close()
# メイン処理の統合
def get_and_cache_news(query):
init_db() # DB初期化を忘れずに
last_fetch_time_str = get_last_fetched_time(query)
from_date = None
if last_fetch_time_str:
# NewsAPIのfromパラメータは日付形式なので、時刻部分は切り捨て
from_date = datetime.fromisoformat(last_fetch_time_str).strftime("%Y-%m-%d")
# NewsAPIから新規記事を取得
new_articles = fetch_news_with_retry(query, from_date=from_date)
if new_articles:
save_articles_to_cache(new_articles)
update_last_fetched_time(query)
print(f"{len(new_articles)}件の新規記事をキャッシュに保存しました。")
else:
print("新規記事はありませんでした。")
# キャッシュから全ての記事を取得して利用
conn = sqlite3.connect(DATABASE_FILE)
cursor = conn.cursor()
cursor.execute("SELECT published_at, title, url FROM articles ORDER BY published_at DESC")
all_cached_articles = cursor.fetchall()
conn.close()
return all_cached_articles
# 使用例
# print("--- キャッシュと差分更新を考慮したニュース取得 ---")
# cached_news = get_and_cache_news("株価 上昇")
# for date, title, url in cached_news:
# print(f"{date[:10]} - {title}")このコードでは、init_db()で必要なテーブルを作成し、get_and_cache_news()関数が、前回の取得日時を参考にNewsAPIから差分データを取得し、キャッシュに保存する一連の流れを担います。これにより、APIリクエストを最小限に抑えつつ、常に最新のデータを手元に保持できるようになります。
TF-IDFを実用レベルに引き上げる!金融ニュース特化型チューニング
収集したニュース記事から重要なキーワードを抽出するTF-IDF(Term Frequency-Inverse Document Frequency)については、以前の記事で基本的な解説をしました。ここでは、株価ニュース分析という特定のドメインにおいて、TF-IDFの精度をさらに高めるためのチューニング方法に焦点を当てます。
まず、日本語のテキストを扱うため、形態素解析ライブラリJanomeをインストールしておきましょう。
pip install Janome scikit-learnノイズを除去する「カスタムストップワード」の重要性
TF-IDFは、文書内で頻繁に出現し、かつ他の多くの文書ではあまり出現しない単語の重要度を高めます。しかし、金融ニュースという特定の分野では、「株価」「市場」「上昇」「下落」「企業」「投資」といった単語が非常に頻繁に出現します。これらの単語は重要ではあるものの、どのニュースにも共通して出てくるため、特定のニュース記事の「独自性」や「株価への影響度」を測る上では、かえってノイズになってしまうことがあります。
プロの分析では、このようなドメイン固有のノイズを「カスタムストップワード」として定義し、TF-IDFの計算から除外します。
from janome.tokenizer import Tokenizer
from sklearn.feature_extraction.text import TfidfVectorizer
# 金融ニュース特有のカスタムストップワードリスト
# ここにさらに多くの頻出語を追加することで精度を高めます
CUSTOM_STOPWORDS = [
'株価', '市場', '上昇', '下落', '円', 'ドル', '企業', '投資', '経済',
'発表', '見通し', '決算', '速報', '報道', 'ニュース', '関係者', 'によると',
'金融', '政策', '政府', '業界', '事業', '開発', '社長', '会長', '億円', '万株',
'開始', '終了', '予定', '今回', '今回', '昨年', '今年', 'これ', 'これら', 'それ', 'その',
'など', 'また', '一方', 'さらに', 'しかし', 'そして', 'ため', 'こと', 'もの', 'よう', 'られる', 'できる'
]
t = Tokenizer()
def tokenize_and_filter(text):
"""形態素解析を行い、名詞・動詞・形容詞を抽出し、カスタムストップワードを除外"""
tokens = []
for token in t.tokenize(text):
part_of_speech = token.part_of_speech.split(',')[0]
# 名詞、動詞、形容詞のみを対象とし、カスタムストップワードを除外
if part_of_speech in ['名詞', '動詞', '形容詞'] and token.surface not in CUSTOM_STOPWORDS:
tokens.append(token.surface)
return " ".join(tokens)
# 使用例 (TF-IDF計算の前処理として)
# cached_news_data = [item[1] for item in cached_news] # キャッシュからタイトルなどを取得
# processed_texts = [tokenize_and_filter(text) for text in cached_news_data]
# vectorizer = TfidfVectorizer()
# tfidf_matrix = vectorizer.fit_transform(processed_texts)
# feature_names = vectorizer.get_feature_names_out()
# print(f"TF-IDFで抽出された特徴語の数: {len(feature_names)}")この一手間を加えることで、「半導体不足」「サプライチェーン」「新技術開発」「M&A」といった、より本質的で株価への影響が大きいキーワードが浮き彫りになりやすくなります。
複合語を捉える「N-gram」の活用
日本語の金融ニュースでは、「利上げ」「下方修正」「株主還元」「金融緩和」のように、複数の単語が組み合わさって初めて意味をなす「複合語」が非常に重要です。単一の単語として「利」や「上げ」だけを抽出しても、その真意を捉えることはできません。
ここで活用するのが「N-gram(エヌグラム)」という手法です。N-gramは、テキストをN個の単語の連なりとして分割します。
- ユニグラム (1-gram): 「利」「上げ」「下方」「修正」
- バイグラム (2-gram): 「利上げ」「下方修正」「株主還元」
- トライグラム (3-gram): 「金融政策決定会合」
TfidfVectorizerは、ngram_rangeパラメータを指定することで、N-gramを考慮したTF-IDF計算が可能です。
from janome.tokenizer import Tokenizer
from sklearn.feature_extraction.text import TfidfVectorizer
t = Tokenizer()
def tokenize_for_ngram(text):
"""形態素解析を行い、単語のリストを返す"""
# ここではカスタムストップワード除外はVectorizerのngram_rangeと組み合わせて行う
return [token.surface for token in t.tokenize(text) if token.part_of_speech.split(',')[0] in ['名詞', '動詞', '形容詞']]
# TF-IDF Vectorizerの設定
# ngram_range=(1, 2) でユニグラムとバイグラムを両方考慮
# stop_words=CUSTOM_STOPWORDS でカスタムストップワードを除外
vectorizer_ngram = TfidfVectorizer(
tokenizer=tokenize_for_ngram, # Janomeで前処理
ngram_range=(1, 2), # ユニグラムとバイグラムを考慮
stop_words=CUSTOM_STOPWORDS # カスタムストップワードを除外
)
# 使用例
# processed_texts = [cached_article[1] for cached_article in cached_news] # ニュースタイトルなど
# tfidf_matrix_ngram = vectorizer_ngram.fit_transform(processed_texts)
# feature_names_ngram = vectorizer_ngram.get_feature_names_out()
# print(f"N-gramとカスタムストップワード適用後の特徴語の数: {len(feature_names_ngram)}")
# print("上位の特徴語の例:", feature_names_ngram[:20]) # 例として上位20件表示N-gramとカスタムストップワードを組み合わせることで、ニュースの意図やセンチメントをより精密に捉え、株価への影響を予測するための強力な特徴量を生成できます。
PM’s Eye 2: APIは常に変化する「生き物」:仕様変更との賢い付き合い方
外部APIを利用するシステムを構築する上で、最も厄介な問題の一つが「APIの仕様変更」です。提供元がサービスを改善したり、料金体系を変更したりする際に、APIのURL、パラメータ、応答フォーマットなどが予告なく変更されることがあります。
私はかつて、何の対策もせずに外部APIに依存したシステムを構築し、ある日突然、API側の仕様変更でシステムが完全に停止した経験があります。その時は、原因不明のバグとして何日も徹夜で調査し、最終的にAPIのドキュメントが更新されていたことに気づいた時には、冷や汗が止まりませんでした。ビジネスへの影響も大きく、苦い教訓となりました。
このような事態に備えるためには、以下のような対策が不可欠です。
- 疎結合な設計: API呼び出し部分を独立したモジュールやサービスとして切り出し、他のシステム部分への影響を最小限に抑えます。これにより、APIの変更があっても、影響範囲を限定しやすくなります。
- バージョン管理: 可能な限り、APIのバージョン指定(例:
/v2/)を利用し、古いバージョンがすぐに廃止されないか確認します。 - ドキュメントの定期チェック: APIプロバイダーからのメール通知や公式ドキュメントを定期的に確認する運用体制を構築します。
- 監視とアラート: API呼び出しのエラー率が急増した場合など、異常を早期に検知できる監視体制を整えることが最も重要です。
APIは常に進化する「生き物」です。その変化に対応できるよう、常にアンテナを張り、システム設計に柔軟性を持たせておくことが、プロの現場では求められます。
運用編:安定稼働を支える運用設計の要点
堅牢なコードと高精度な分析ロジックが完成しても、それだけでは「運用できるシステム」とは言えません。最後に、安定稼働を支えるための運用設計の要点について解説します。
「何かあった時」に備えるロギング設計
システムが正常に動作しているか、あるいは問題が発生していないかを把握するためには、「ログ」が不可欠です。エラーが発生した時に、いつ、どこで、どのようなエラーが起きたのかが分からなければ、原因究明は困難を極めます。
Pythonの標準ライブラリであるloggingモジュールを使えば、簡単にロギング機能を実装できます。
import logging
# ロガーの設定
# ファイルに出力し、INFOレベル以上のログを記録
logging.basicConfig(
filename='news_analysis.log',
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
logger = logging.getLogger(__name__)
# 使用例
# logger.info("システムが起動しました。")
# try:
# # ここにNewsAPI呼び出しなどの処理
# get_and_cache_news("株価 上昇")
# logger.info("NewsAPIからのデータ取得とキャッシュが完了しました。")
# except requests.exceptions.HTTPError as e:
# logger.error(f"HTTPエラーが発生しました: {e.response.status_code} - {e.response.text}")
# except Exception as e:
# logger.exception("予期せぬエラーが発生しました。") # tracebackも出力される
# logger.info("システムが終了しました。")ロギングでは、INFO(情報)、WARNING(警告)、ERROR(エラー)、CRITICAL(致命的)といったログレベルを適切に使い分け、必要な情報を過不足なく記録することが重要です。クラウド環境であれば、AWS CloudWatch LogsやGoogle Cloud Loggingのようなサービスと連携させることで、ログの集約・分析が容易になります。
システムの異変を早期に検知する監視とアラート
ログは重要ですが、ログファイルを手動で毎日確認するのは非現実的です。プロの現場では、システムの稼働状況を常時チェックし、異常を検知した際に自動で通知する「監視(モニタリング)とアラート」の仕組みを導入します。
監視すべき項目としては、以下のようなものが挙げられます。
- APIリクエスト数: NewsAPIの無料枠上限に近づいていないか。
- エラー発生率: API呼び出しやデータ処理でエラーが頻発していないか。
- 処理時間: データ取得から分析までの時間が異常に長くなっていないか。
- キャッシュヒット率: キャッシュが有効に機能しているか。
- ディスク使用量: キャッシュDBやログファイルがディスク容量を圧迫していないか。
これらの項目を定期的にチェックし、設定した閾値を超えた場合に、Slackやメール、PagerDutyなどを通じて開発者や運用担当者にアラートを飛ばすことで、システムの問題を早期に発見し、迅速に対応することが可能になります。
まとめ:プロの視点で「運用できるシステム」を構築する
NewsAPIとTF-IDFは、株価ニュース分析の強力なツールです。しかし、その真価は、単に「動くコードを書く」ことではなく、「いかにプロとして、堅牢性、拡張性、運用性を考慮したシステムを設計・構築するか」にかかっています。
この記事では、以下のような「本物のシステム開発の思考法」をお伝えしました。
- 一時的なエラーに強い「指数バックオフ」を用いたリトライ処理
- API制限を賢く回避する「差分取得」と「キャッシュ設計」
- 金融ニュースに特化した「カスタムストップワード」と「N-gram」によるTF-IDFチューニング
- 外部APIの変更リスクに備える「PM視点の設計思想」
- 「動くコード」の先に存在する「運用可能なシステム」を構築するための「ロギング」と「監視・アラート」
これらの知見は、NewsAPIやTF-IDFに限らず、あらゆるソフトウェア開発プロジェクトに応用できる普遍的なものです。
もしあなたが、単なるツールの使い方を覚えるだけでなく、一歩先のシステム開発者を目指したいのであれば、ぜひ今回の内容を自身のプロジェクトに活かしてみてください。きっと、あなたの開発スキルと視座は大きく向上するはずです。
これからも、私の長年の経験から得た知見が、皆さんの学びの一助となれば幸いです。



